
A high level overview of data analysis with tools like Dune, Python, SQL & DuckDB
Introduction
In practical, data analysis requires the data team to acquire reliable data and cleaning of the data to make sense of the insights extracted from the data.In our last article, we looked at the different types of data that can be produced on a decentralized network.

The challenges with analyzing Blockchain data comes from not only the built in security measures but also from the very nature of the protocols used to develop the chains. To understand it better, let's have a look at one of the chains called Ethereum.Ethereum is a blockchain powered by smart contracts that are executed when a transaction is triggered. Smart Contracts can be used to build anything like a digital currency, lending apps, NFTs, social networks and distributed apps, etc.The wide use cases of the Ethereum Blockchain means it can be used to generate a wide range of data as well.Let's have a look at the type of data that can be exported from a Ethereum Blockchain.
Type of Data on Ethereum Blockchain
The data on a blockchain is stored as series of blocks on the chain or through integrated solutions. There are two types of Ethereum Accounts -
- Externally Owned Acounts (EOA) - That store the private keys of accounts participating in a transaction along with additional data that the accounts will share between them.
- Contract Accounts - That store details regarding the smart contracts that govern the chain and can be managed programmatically.
For Data Analysis, a data engineer should be aware about the structure of the data and the way protocols work on the chain. Below is a list of type of data that can be exported from Ethereum chain -
- Blocks
- Transactions
- ERC20 / ERC721 tokens
- Token Transfers
- Receipts
- Logs
- Contracts
- Internal Transactions (traces)
All these different types of data can be browsed with services like etherscan.io, Dune Analytics, etc. Some of these data types need to be labelled before it can be made sense in a dashboard.Let's have a look at Dune Analytics and how easy it is to browse Ethereum data in the tool.
Dune Analytics and the magic of SQL
Dune is a hub for Web3 related data. It allows us to analyze on-chain, near real time data and also keep track of historical data on any chain using familiar language like SQL.As a Data Analyst, it is very helpful to work with the queries in the app itself, and then use API to export the results into any database I want for further analysis.Let's see an example of working within the app and building a query and visualization-
Queries in Dune Analytics
The best way to get started in Dune is to find the pool of content specific to a Blockchain and use their inbuild tables to run simple SQL queries.In the below query, we are combining Ethereum Transaction data with another table called ens in the labels database that allows us to attach a domain name to a transaction wallet.
WITH transaction_data AS (
SELECT block_time, block_number, value, gas_limit, gas_price, gas_used, "from", "to", block_date
FROM ethereum.transactions
),
labelled_data AS (
SELECT blockchain, address, name, category, created_at, updated_at
FROM labels.ens
)
SELECT td.block_number, td.value, td."from", td."to", ld.blockchain, ld.address, ld.name
FROM transaction_data td
LEFT JOIN labelled_data ld ON td."from" = ld.address
LIMIT 100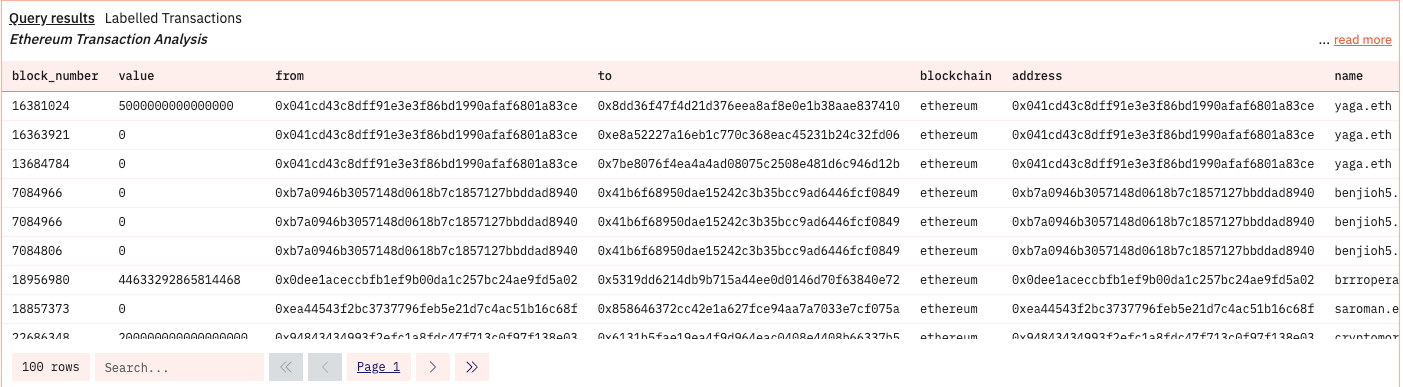
The above chart shows block level representation of the query that was executed. The visualization is auto-created and native to the dune app.
Calculating the Gas Fee % natively in Dune
The below query is another example of working in the Dune app to calculate the gas fee utilization percentage for each block to determine the efficiency of the chain.The higher the gas utilization percentage, the more power is required to solve the block for integrity.
SELECT
block_number,
gas_limit,
gas_used,
type,
ROUND(gas_used * 100.0 / gas_limit, 2) AS gas_utilization_pct,
block_date
FROM ethereum.transactions
ORDER BY block_date
LIMIT 100;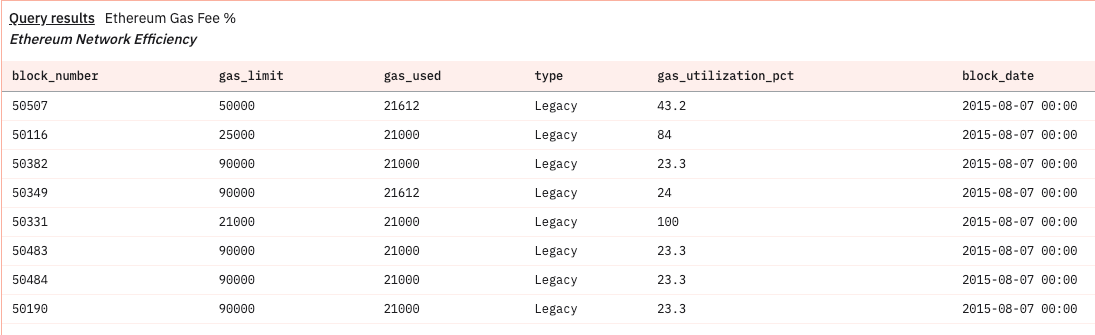
The above table shows us that the gas utilization is consistent for most blocks but some anomalies can be detected and analyzed for optimization & correction.For more complex analysis, the data needs to be moved to performance optimized analytical databases.Let's have a look at analyzing the data on database like DuckDB.
Exploratory Analysis with DuckDB & Motherduck
For Exploratory and further Data Analysis and implementing Machine Learning Algorithms into the system, the data can be exported into formats well known to analytical databases.As we traversed through Ethereum Data in Dune Analytics, we can access the same queries from Dune and download the data into csv format.Here is the code that is accessing the queries fro Dune Analytics -
import pandas as pd
from dune_client.client import DuneClient
import duckdb
def extract_data():
"""
Extracts data from a Dune Analytics API and returns it as a pandas DataFrame.
The Pandas DataFrame is then loaded into a DuckDB database.
"""
try:
API_KEY = <<YOUR API KEY>>
db_path = <<DB PATH>>
dune = DuneClient(API_KEY)
results_df = dune.get_latest_result_dataframe('<<DUNE QUERY ID>>')
print("Data extracted successfully from Dune client")
con = duckdb.connect(database=db_path, read_only=False)
con.execute("CREATE TABLE IF NOT EXISTS dune_data AS SELECT * FROM results_df")
print("Data loaded to duckdb successfully")
except Exception as e:
print(f"Error extracting data from dune client")
def main():
"""
Main function to run the data extraction.
"""
extract_data()
if __name__ == "__main__":
main()
print("Running data extraction pipeline...")
print("Data extraction completed successfully.")The above code loads the data in a DuckDB. DuckDB is a analytical database which is stored as a file locally so it can be easily accessed and moved.In addition, the database can be accessed via UI with a single command -
duckdb -uiThis command opens a UI window. The DuckDB file can then be attached as a database and analysis can be done with SQL.
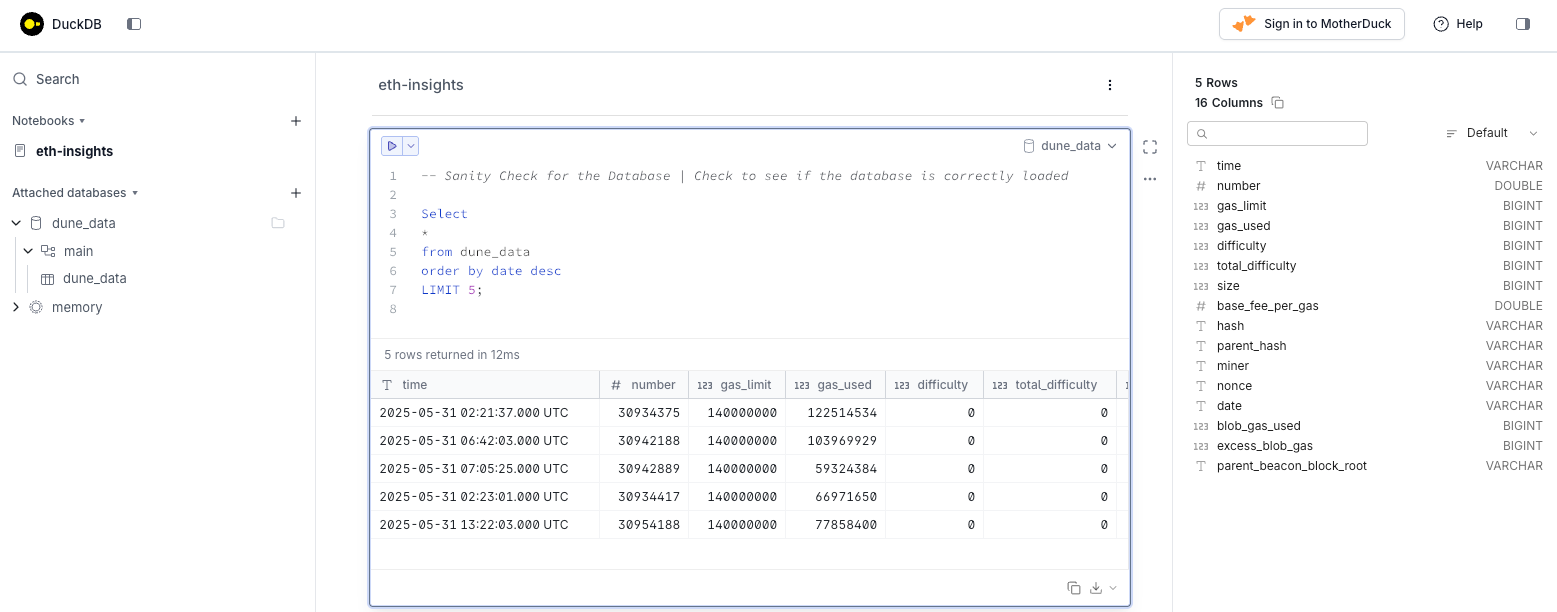
Data Analysis in DuckDB
Let's run some exploratory analysis with DuckDB in the MotherDuck UI.
– Miner with high block count.
SELECT
miner,
COUNT(*) AS block_count
FROM dune_data
GROUP BY miner
ORDER BY block_count DESC;
The above query reads through the data and returns blocks mined in descending order.
– Base fee per gas for blocks over time
SELECT
date,
AVG(base_fee_per_gas) AS avg_base_fee
FROM dune_data
GROUP BY date
ORDER BY date;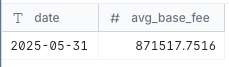
The above query reads through the data and returns the average of gas fees paid on a particular date.
– Calculate gas utilization % for each block
SELECT
number,
size,
gas_limit,
gas_used,
ROUND(gas_used * 100.0 / gas_limit, 2) AS gas_utilization_pct,
time
FROM dune_data
ORDER BY gas_utilization_pct desc;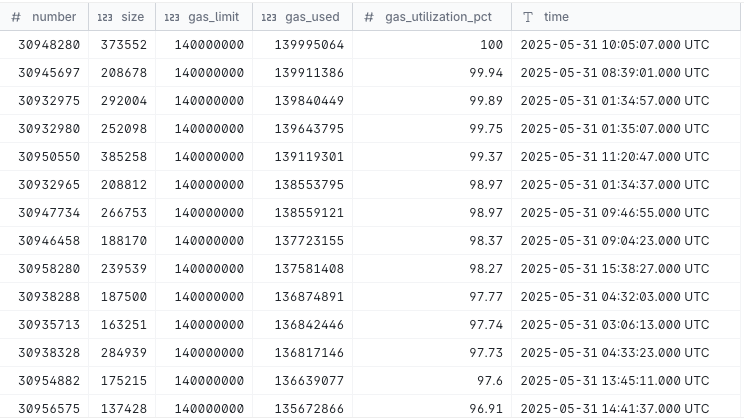
The above query is similar to the one we saw before in Dune Analytics where it returns the gas utilized percentage for each block to understand where the network can be optimized.
In addition to the above queries, using a simple python script, the queries and the results in Dune Analytics can be accessed and analysis can be done in a typical Analytical Database.
Question here is that whether there is easier way to create a Data Pipeline that reads Ethereum data with CDC (Change Data Capture) implemented for long term & sustained analysis.
Implementing Data Engineering Pipeline with Ethereum ETL
The answer to above question is - YES!A library called Ethereum ETL can be used to implement robust data pipeline to download real time or near real time data from Ethereum chains or Cloud Data Storage like Google BigQuery and Amazon Athena.
pip install ethereum-etlThe command will install the Etherum ETL library in a python notebook or project.The library comes with few inbuilt commands which can be used to download varied data from Ethereum Blockchain.
ethereumetl export_blocks_and_transactions --start-block 0 --end-block 500000 \--provider-uri https://mainnet.infura.io/v3/7aef3f0cd1f64408b163814b22cc643c --blocks-output blocks.csv --transactions-output transactions.csvThe above command downloads the ethereum transaction blocks and stores it in a csv files.
As we did with the dataset from Dune and DuckDB, we can create a similar analysis with Ethereum ETL as well.
I will cover implementation of Data Pipeline with Ethereum ETL, Google BigQuery and DuckDB with data quality rules in my next post.
Conclusion
As we saw in the post, working with Blockchain data can get complicated.
It is not just the data analysis part but also data ingestion, cleaning and orchestration needs knowledge about Blockchain and the protocol used for the implementation.
We will cover more on this topic in upcoming posts in detail.
